Hi,
When parsing/serializing the same model twice in jupyter (with restart kernel in between),
the nodes get (mostly) the same UUIDs every time, except root namespaces, expressions and literalIntegers. They get new IDs.
But AttributeUsages have the same ID and then point to all of the new literals and have multiple relationships.
That messes up visualizations like TomSawyer.
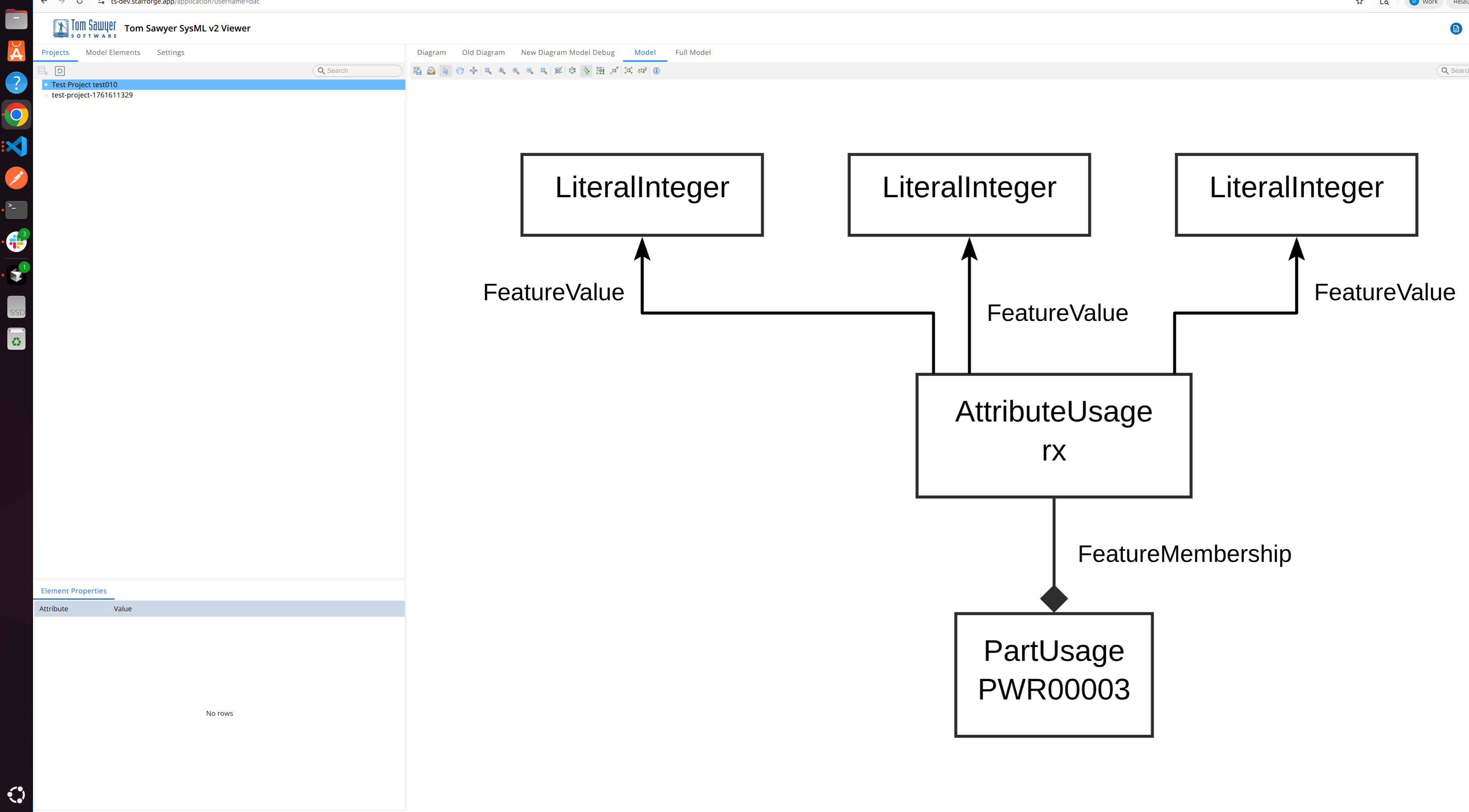
I thought that every serialization creates new UUIDs every time.
Can you shed some light on this?
Thanks!
cc @Dat_Nguyen